https://www.opinet.co.kr/
싼 주유소 찾기 오피넷
www.opinet.co.kr
1. 서울시 구별 주유소 가격 정보 얻기
Selenium을 사용해서 웹크로링으로 해당 웹페이지에서 주유소 가격 정보를 얻어온다.
먼저, Webdriver에서 Selenium을 import합니다. 오류가 많이 나기 때문에 아래 코드에 있는 것들을 다 import 해줍니다.
from urllib . request import urlopen
from selenium import webdriver
from selenium . webdriver import ActionChains
from selenium . webdriver . common . keys import Keys
from selenium . webdriver . common . by import By
from selenium . webdriver . support import expected_conditions as EC
from selenium . webdriver . support . ui import Select
from selenium . webdriver . support . ui import WebDriverWait
from selenium import webdriver
from selenium . webdriver . chrome . service import Service as ChromeService
from selenium . webdriver . chrome . options import Options as ChromeOptions
from webdriver_manager . chrome import ChromeDriverManager
options = ChromeOptions ()
# 크롬 드라이버 최신 버전 설정
service = ChromeService ( executable_path = ChromeDriverManager (). install ())
# chrome driver
driver = webdriver . Chrome ( service = service )
아래 코드를 쓰면 크롬이 켜집니다.
driver = webdriver . Chrome ()
get함수를 사용해 url을 인자로 주어서 사이트에 들어갑니다.
웹페이지에 들어가서 F12버튼을 눌러 개발자 도구에 들어가서 왼쪽 상단에 화살표 버튼을 눌러줍니다. 해당 부분에 마우스로 클릭하면 우리가 원하는 구만 들어있는 Elements를 볼 수 있습니다. 해당 id는 SIGUNGU_NMO 이고 하위 목록은 value값으로 되어있습니다. 우리는 저 value값을 가져와야합니다.
그 후, find_element를 사용하여 찾고자 하는 element를 넣어줍니다. 그 후에 value값은 여러개 있기 때문에 find_elements를 사용해줍니다. 또한, value값의 상위에 있는 id를 가지고 있는 Element는 XPATH로 id를 집어넣어 찾아주고, 그 XPATH에서 CSS_SELECTOR가 option인 Element값들을 gu_list에 할당해 줍니다.
gu_list_raw = driver . find_element ( By . XPATH , """//*[@id="SIGUNGU_NM0"]""" )
gu_list = gu_list_raw . find_elements ( By . CSS_SELECTOR , "option" )
아래 결과값처럼 gu_list_raw는 WebElement값이고, gu_list는 value값들의 WebElement값들이 담겨져 있는 List입니다.
아래와 같이 Element.get_attribute()를 사용하면 해당 Element가 가진 값을 볼 수 있습니다.
따라서, 아래 코드와 같이 for문을 사용하여 구이름을 뽑아냅니다.
my_gu_names = []
for a in gu_list :
my_gu_names . append ( a . get_attribute ( "value" ))
my_gu_names
my_gu_names . remove ( '' )
my_gu_names
=>
여기서 이 코드를 한 라인으로 짤 수 있습니다.
gu_names = [ a . get_attribute ( "value" ) for a in gu_list ]
해석: gu_list에 있는 값 한 개씩 a로 받아서 get_attribute("value")를 사용해 값을 반환받습니다. 그런 다음 마지막으로 []를 사용해 리스트화 시켜줍니다.
이제, find_element로 할당할 부분을 지정해주고 gu_name의 첫번째 값인 '강남구'를 send_keys로 넣어봅시다.
element = driver . find_element ( By . ID , "SIGUNGU_NM0" )
element . send_keys ( gu_names [ 0 ])
아래 그림처럼 강남구라는 글자가 들어갔습니다.
그럼 조회버튼을 눌러봅시다. 조회버튼의 XPath는 id가 searRgSelect입니다. 따라서아래 코드와 같이 send_key 함수에 ENTER 키를 넣어주어 클릭합니다. (find_element로 찾고 .click()해도 되지만, 저는 클릭이 안되서 방법을 찾다가 해당 방법을 찾았습니다.)
xpath = """//*[@id="searRgSelect"]"""
driver . find_element ( By . XPATH , xpath ). send_keys ( Keys . ENTER )
똑같이 엑셀 저장도 해줍니다.
xpath = """//*[@id="glopopd_excel"]"""
driver . find_element ( By . XPATH , xpath ). send_keys ( Keys . ENTER )
TQDM NOTEBOOK TQDM은 작업 중에 커널이 잘 살아있는지 확인하기 위해 진행도를 보여주는 모듈입니다.
for문을 돌릴 때 작업이 언제끝나는지 확인도 가능하며 언제까지 진행되는지도 볼 수 있습니다.
https://velog.io/@hyunicecream/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EC%9C%A0%EC%9A%A9%ED%95%9C-%EA%B8%B0%EB%8A%A5-tqdm-and-tqdmnotebook
tqdm이란? tqdm and tqdm.notebook 사용방법
안녕하세요. 데이터 작업을 할때 유용한 라이브러리인 tqdm 과 tqdm notebook에 대해 설명드리겠습니다.tqdm은 Python에서 Progress Meter 또는 Progress Bar를 만드는 데 사용되는 라이브러리입니다.tqdm은 loop
velog.io
대게 for문을 사용할 때 tqdm을 넣어 사용하게 되는데, jupyter에서는 아래코드와 같이 tqdm_notebook으로 사용한다.
혹시 모르니, 아래와 같이 오류에 대한 방지를 해준다.
import time
from tqdm import tqdm_notebook
import warnings
warnings.filterwarnings(action='ignore')
import ipywidgets
from tqdm.notebook import tqdm
import jupyterlab_widgets
from selenium.common.exceptions import NoSuchElementException
for gu in tqdm_notebook ( gu_names ):
element = driver . find_element ( By . ID , "SIGUNGU_NM0" )
element . send_keys ( gu )
time . sleep ( 2 )
xpath = """//*[@id="glopopd_excel"]"""
driver . find_element ( By . XPATH , xpath ). send_keys ( Keys . ENTER )
time . sleep ( 2 )
2. 구별 주유 가격에 대한 데이터 정리
glob 모듈을 사용해서, 다운받은 xls 데이터를 한번에 불러오는 작업을 수행한다.
glob모듈은 SQL 에서 LIKE '%' 와 비슷한 기능을 한다. * 문자로 파일명이 비슷할 때 주로 사용한다.
station_files 변수에 할당해주고, 이제 for문과 read_excel을 사용해 데이터를 입력받는다.
그렇게 되면 리스트 안에 Dataframe형태로 데이터가 저장되는 형태이다. [주유소 정보(1)DataFrame, 주유소 정보(2)DataFrame ...] 그 후에 concat함수를 통해 데이터를 합쳐 준다. 그 후에 reset_index 함수를 통해 index를 새로 만들어 주고, 원래 있던 index 컬럼은 삭제한다.
stations_files = glob ( '../data/지역*.xls' )
stations_files
tmp_raw = [pd.read_excel(x, header = 2 , index_col = False ) for x in stations_files]
stations_raw = pd.concat(tmp_raw)
stations_raw.reset_index( inplace = True )
del stations_raw[ 'index' ]
stations_raw
# 위 코드와 같은 코드
# for file_name in stations_files:
# tmp = pd.read_excel(file_name, header=2)
# tmp_raw.append(tmp)
# stations_raw = pd.concat(tmp_raw)
그 후에 rename 함수를 사용해 컬럼명을 변경한다.
stations = stations_raw . loc [:,[ '상호' , '주소' , '휘발유' , '셀프여부' , '상표' ]]. rename (
columns = {
'상호' : 'Oil_store' ,
'휘발유' : '가격' ,
'셀프여부' : '셀프'
}
)
stations . head ()
=>
그 후에, 주소에서 구정보만 뽑아내기 위해 split함수로 분리시켜 2번째 값만 가지고와서 List화 해주고 stations['구'] 컬럼을 만든다.
stations [ '구' ] = [ eachAddress .split()[ 1 ] for eachAddress in stations [ '주소' ]]
stations . head ()
=>
그리고, 가격 컬럼에 - 라는 값이 들어있어서 해당 값을 제외한 데이터들로만 다시 재구성 하는 전처리를 해준다.
stations = stations [ stations [ '가격' ] != '-' ]
그 후에, 가격 컬럼이 object이기 때문에 astype함수로 float으로 형변환을 해준다.
stations [ '가격' ] = stations [ '가격' ]. astype ( float )
stations . info ()
3. 셀프 주유소 정말 저렴한지 boxplot으로 확인하기
seaborn 모듈로 상표별 가격을 셀프주유소 별로 시각화하여 확인해본다.
plt . figure ( figsize = ( 12 , 8 ))
sns . boxplot ( x = '상표' , y = '가격' , hue = '셀프' , data = stations , palette = "Set3" )
plt . show ()
=> 현대오일뱅크, GS칼텍스, S-Oil, SK에너지, 알뜰주유소 모두 셀프 주유소가 저렴하다. 그 중 GS칼텍스는 가장 가격대가 높게 형성되어 있는 것을 볼 수 있다.
Swarmplot을 같이 그려 상표별로 데이터 분포를 알아보자.
plt . figure ( figsize = ( 12 , 8 ))
sns . boxplot ( x = '상표' , y = '가격' , data = stations , palette = "Set3" )
sns . swarmplot ( x = '상표' , y = '가격' , data = stations , color = ".6" )
plt . show ()
=> GS칼텍스와 SK에너지가 가장 높은 가격대로 형성되어 있고, 그나마 S-Oil와 현대 오일뱅크는 낮은 가격대로 형성되어 있는것을 볼 수 있다.
3. 서울시 구별 주유 가격 확인하기
필요한 모듈을 import 해줍니다.
import json
import folium
import googlemaps
import warnings
warnings.simplefilter( action = "ignore" , category = FutureWarning )
서울시에서 가장 가격이 비싼 주유소 10개와 가장 싼 주유소 10개를 확인
그 후에, Pivot함수를 사용하여 구별로 평균 가격을 확인합니다.
gu_data = pd.pivot_table(stations, index = [ '구' ], values = [ '가격' ], aggfunc = 'mean' )
gu_data.head()
=> 강남구 > 강동구 > 강북구 순으로 주유 가격이 비쌉니다.
아래 코드와 같이 포리움 함수로 매핑해줍니다.
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load( open (geo_path, encoding = 'utf-8' ))
map = folium.Map( location = [ 37.5502 , 126.982 ], zoom_start = 10.5 ,
tiles = 'Stamen Toner' )
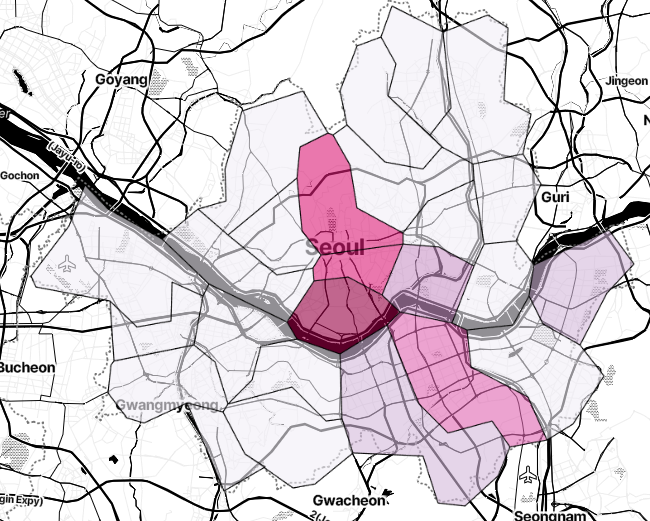
map .choropleth( geo_data = geo_str,
data = gu_data,
columns = [gu_data.index, '가격' ],
fill_color = 'PuRd' , #PuRd, YlGnBu
key_on = 'feature.id' )
map
분명 강남이 가장 높아야 되는데 왜저렇게 매핑되는지 의문점이다..
아래 코드와 같이 top10과 bottom10 변수를 할당해 줍니다.
oil_price_top10 = stations.sort_values( by = '가격' , ascending = False ).head( 10 )
oil_price_top10
oil_price_bottom10 = stations.sort_values( by = '가격' , ascending = True ).head( 10 )
oil_price_bottom10
gmaps를 쓰기 위해 구글 지도 API key값을 받아옵니다.
gmpas_key = "*******************************************"
gmpas = googlemaps.Client( key = gmpas_key)
그리고, gmpas.geocode로 주소별 지오코드 정보를 얻어와 위경도 정보를 가지고 옵니다.
from tqdm import tqdm_notebook
lat = []
lng = []
for n in tqdm_notebook(oil_price_top10.index):
try :
tmp_add = oil_price_top10[ '주소' ][n].split( '(' )[ 0 ]
tmp_map = gmpas.geocode(tmp_add)
tmp_loc = tmp_map[ 0 ].get( 'geometry' )
lat.append(tmp_loc[ 'location' ][ 'lat' ])
lng.append(tmp_loc[ 'location' ][ 'lng' ])
except :
lat.append(np.nan)
lng.append(np.nan)
print ( "Here is nan !" )
oil_price_top10[ 'lat' ] = lat
oil_price_top10[ 'lng' ] = lng
oil_price_top10
=>
bottom10 에 대해서도 수행합니다.
lat = []
lng = []
for n in tqdm_notebook(oil_price_bottom10.index):
try :
tmp_add = oil_price_bottom10[ '주소' ][n].split( '(' )[ 0 ]
tmp_map = gmpas.geocode(tmp_add)
tmp_loc = tmp_map[ 0 ].get( 'geometry' )
lat.append(tmp_loc[ 'location' ][ 'lat' ])
lng.append(tmp_loc[ 'location' ][ 'lng' ])
except :
lat.append(np.nan)
lng.append(np.nan)
print ( "Here is nan !" )
oil_price_bottom10[ 'lat' ] = lat
oil_price_bottom10[ 'lng' ] = lng
oil_price_bottom10
=>
folium함수와 for문으로 가장 비싼/싼 주유소의 위치를 CircleMarker로 매핑해줍니다.
map = folium.Map( location = [ 37.5202 , 126.975 ], zoom_start = 10.5 )
for n in oil_price_top10.index:
if pd.notnull(oil_price_top10[ 'lat' ][n]):
folium.CircleMarker([oil_price_top10[ 'lat' ][n], oil_price_top10[ 'lng' ][n]],
radius = 15 , color = '#CD3181' ,
fill_color = '#CD3181' ,
fill = True ).add_to( map )
for n in oil_price_bottom10.index:
if pd.notnull(oil_price_bottom10[ 'lat' ][n]):
folium.CircleMarker([oil_price_bottom10[ 'lat' ][n],
oil_price_bottom10[ 'lng' ][n]],
radius = 15 , color = '#3186cc' ,
fill_color = '#3186cc' ,
fill = True ).add_to( map )
map
=> 데이터로 보았을 때랑 매핑이 잘못된듯 한걸 보니, 위경도에 문제가 있는것 같습니다.
여기까지 웹크롤링을 사용해서 Python을 사용해 보았습니다.
이 책에서는 버젼문제와 구글지도 매핑 문제가 있어서 해석의 오류가 발생하니, 지도 시각화 부분은 앞으로 제외하고 게시하도록 하겠습니다.
본 내용은 파이썬으로 데이터 주무르기-민형기 책에서 공부한 내용을 바탕으로 작성한 글입니다.