
Ethan's Values
파이썬 데이터 주무르기 1장 서울시 구별 CCTV 현황 분석 본문
1. 서울시의 구별 CCTV 현황 분석
- 어디에 CCTV가 많이 설치됐는지
- 구별 인구 대비 비율
먼저, CCTV 데이터와 서울시 인구 데이터를 다운받는다.
데이터는 서울시 열린데이터 광장에서 받을 수 있지만, 저자의 Git에서 받기로 한다.
https://github.com/PinkWink/DataScience/tree/master/data
read_csv로 csv파일을 읽어올 때, 왠만하면 글자가 깨질 수 있으니 encoding 이 필요하다.
cp949, utf-8, utf-8-sig중 한개일 것이다.
->

Pandas 기초 다지기
날짜형식의 데이터 생성하기
아래와 같이 pandas의 date_range함수를 써서 periods(기간) 인자를 주면 지정한 날짜로 부터 정한 갯수 날만큼 생성된다.
->

정규분포된 난수로 DataFrame 생성하기
numpy의 np.random.randn()함수로 정규분포된 난수를 생성하고 해당 값으로 Dataframe을 만들 수 있다.
randn(A,B) A와 B는 각 생성하려는 행의 갯수, 열의 갯수를 의미한다. 아래에는 index = dates로 index값을 사전에 만들어놓은 dates를 불러와 index 값으로 지정한다.
->

데이터 포함 여부 조건을 사용해 원하는 문자가 포함된 데이터 찾기
아래 데이터에서 E열의 two와 four가 있는 데이터만 추출
isin함수를 사용하여 추출함.
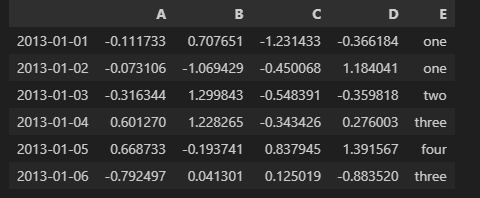
->
->

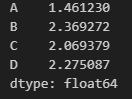
apply함수 사용법
apply(함수,axis=0 or 1), axis의 default는 0(열)이며, 1은 행으로 적용됨
cumsum은 누적합산
->

lambda함수 사용법 (one-line함수)
각 열의 최대값 - 최솟값
->
pandas.DataFrame.sum()의 구문
DataFrame.sum(axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs)| axis | 행(axis=0) or 열(axis=1)을 따라 합계 |
| skipna | NaN값(skipna=True)을 제외, NaN값(skipna=False)포함 계산 |
| numeric | numeric_only=True인 경우 float,int,boolean열만 포함 계산 |
분위수 확인하기
describe함수를 이용해서 4분위수를 확인할 수도 있고, 분위수로 조건문을 만들기 위해 quantile()함수를 사용하여 각 컬럼의 분위수를 찾는다. q는 백분위수(예:75% -> 0.75), interpolation은 분위수에 값이 없을때 보간하는 방법
interpolation 방법 =>
liner : i + (j - i) x 비율 [분위수 앞, 뒤 수 간격 * 비율]
lower : i [분위수 앞, 뒤수 중 작은수]
higher : j [분위수 앞, 뒤수 중 큰수]
midpoint : (i+j)÷2 [분위수 앞, 뒤수의 중간값]
nearest : i or j [분위수 앞, 뒤수중 분위수에 가까운 수]
행 삭제하기
DataFrame.drop()함수를 이용하여 원하는 행(Raw)를 삭제한다.

열(Column) 삭제하기
del DataFrame['컬러명']으로 컬럼 삭제한다. OR 필요한 컬럼만 DataFrame[ [ '컬럼1', '컬럼2' ] ]이런식으로 선택해서 재부여해주어도 된다.

CCTV 많은 구 알아보기
->

Scatter Plot에서 데이터를 대표하는 직선 그리기

먼저 위 데이터에서 아래코드와 같이 인구수와 CCTV 설치 개수와의 관계를 알기 위해 scatter함수로 시각화

1. Polyfit 함수로 다항식의 계수 구하기
p = numpy.polyfit(x,y,n)
x: data의 x값(input)
y: x값에 대응하는 output값
n: 다항식의 차수
결과값 p는 내림차순으로 다항식의 계수들의 값을 가진(고차항 계수부터 상수항 순의 배열) 1차원 배열(vector)
x를 인구수 데이터, y에 CCTV설치 개수 데이터를 지정하고 1차식을 fp1에 저장,
결과값은 기울기와 절편값.
2. Poly1d 함수에 대입
위에서 구한 계수를 가지고 함수(function)로 만들어 줘서 입력을 주고 결과를 얻을 수 있어야 직선을 그릴 수 있다.
poly1d()함수를 사용해서 polynomial class를 만들어 주면 된다.
즉, poly1d([3.66574733e-03, 1.74948641e+03])가 되는 것이다.
=> 아래에서 f1은 y = 3.66574733e-03x + 1.74948641e+03 인 함수이다.
*poly1d
(x+1) + (x-1)을 표현해보자면
np.poly1d([1,1]) + np.poly1d([1,-1])
결과는 poly1d([2,0]) 이다. 즉, 2x + 0 이기 때문에 x에 2 가, 절편에 0이 되는 것이다.
3. np.linspace를 사용해 x만들기
linsapce 함수를 사용하여 y값에 들어갈 x값을 선의 형식을 갖도록 하는 데이터를 생성하여 만들어 준다.
위의 scatter에서 인구수의 최소 정도인 100,000 부터 700,000 까지 100개 데이터값 생성
np.linspace(x,y,n)
x: 구간의 시작점
y: 구간 끝점
n: 구간 내 숫자 개수
아래 코드처럼 scatter를 먼저 그린 후, plot함수안에 linspace로 만든 x와 y는 ploy1d로 만든 함수에 x값을 대입해서 나온 값

대표직선(회귀직선)과 차이나는 데이터 시각화
1. 직선이 대표 값 역할을 한다면, 그 경향에서 멀리 있는 지역은 지역명이 함께 나오게 하는 것.
2. 직선에서 멀어질수록 다른 색을 나타내도록 시각화
먼저, 아래 코드와 같이 CCTV 설치 개수 - 위에서 만든 f1 poly1d에 인구수 데이터 대입 값 식으로 오차값을 생성
오차 컬럼을 기준으로 내림차순 정렬된 데이터프레임 변수 생성
*오차를 기준으로 가장 큰것 부터 scatter 점에 text를 넣어 주기 위한 사전 작업임
scatter를 생성할 때 인자에 c에 오차 컬럼을 넣어준다.
colorbar()함수를 통해 오차의 크기를 알 수 있는 차트를 추가해준다.
for문을 이용하여 오차가 가장 큰 순서부터 10개 지역을 plt.text()함수로 지역명을 넣어준다.
plt.text(x,y,text)
x: x값(텍스트가 표출될 x의 위치값)
y: y값(텍스트가 표출될 y의 위치값)
text: 표출될 text대입

현재 2023년을 기준으로 보았을 때, 선의 위쪽에 위치한 강남구, 영등포구, 성동구, 구로구,성북구는 서울 지역 평균 CCTV 설치 비율보다 CCTV가 많이 설치된 지역구입니다.
반대로 강서구, 송파구, 동작구, 노원구, 도봉구는 서울 지역 평균 CCTV 설치 비율보다 CCTV가 적은 수입니다.
+해당 데이터와 지역구별 치안, 경제와 같은 지표를 대표하는 데이터와 함께 분석한다면 CCTV설치가 적은 곳에 지역구에 대한 데이터관점의 인사이트가 나올것 같다.
본 내용은 파이썬으로 데이터 주무르기-민형기 책에서 공부한 내용을 바탕으로 작성한 글입니다.
'Python' 카테고리의 다른 글
| 파이썬 데이터 주무르기 4장 셀프 주유소는 정말 저렴할까? (2) | 2023.10.30 |
|---|---|
| 파이썬 데이터 주무르기 2장 서울시 범죄 현황 분석 (0) | 2023.10.25 |
| Pandas study - pandas 튜토리얼(7) (0) | 2023.10.19 |
| Pandas study - pandas 튜토리얼(6) (2) | 2023.10.19 |
| Pandas study - pandas 튜토리얼(5) (0) | 2023.10.19 |


